A Survey on Deep Learning Techniques for Stereo-based Depth Estimation

范围和分类 SCOPE AND TAXONOMY
本篇论文主要讨论的是基于深度学习的立体深度估计。
深度估计的任务是从一张或者多张图片中获取图像的深度信息,这些图片可能来自同一个视角或者不同的视角。
基于学习的深度重建可以概括为 学习一个预测函数 $f_\theta$ ,从图片集 $I$ 中推断出一个尽量接近未知深度 $D$ 的深度图 $\hat{D}$
换句话说 我们的任务是找到一个方程 $f_\theta$ 让 $\mathcal{L}(I) = d(f_\theta(I),D)$ 最小其中,$\theta$ 是一系列参数,$d(.,.)$ 是描述两张深度图差距的具体方法 $\mathcal{L}$ 则是损失函数
第一类方法
第一类方法通过显式学习如何 匹配或对应 输入图像中的像素 来模仿传统的立体匹配技术。 【只进行匹配(找出相同的像素点),并不是直接得到视差图】 然后,可以将这种对应关系转换为光流或视差图,而光流或视差图又可以将其转换为参考图像中每个像素的深度。
预测器$f$由三个模块组成:特征提取模块、特征匹配和成本聚合模块 以及 视差/深度估计模块.
第二类方法
第二类方法使用端到端训练的pipeline解决立体匹配的问题,又有两个主要的类别:
早期的方法将深度估计表述为回归问题。换句话说,深度图是直接从输入回归的,而不需要在视图之间显式匹配特征。虽然这些方法在运行时简单快速,但它们需要大量的训练数据,这很难获得。
第二类方法模仿传统的立体匹配流程,将问题分解为由 可微分块 组成的几个阶段,从而允许端到端训练。
大量的工作都集中在双目视觉(pairwise)的深度估计,少量的集中在多视角(multi-view)立体匹配
在所有方法中,可以使用细化模块 和/或 渐进重建策略(progressive reconstruction strategies)进一步细化估计的深度图,其中每次 新图像 可用时 都会 细化(refine)重建。
最后,基于深度学习的立体声方法的性能不仅取决于网络架构,还取决于它们接受训练的数据集和用于优化其参数的训练程序。 后者包括损失函数的选择和监督模式的选择,可以用3D标注进行全监督,也可以是弱监督,也可以是自监督。
数据集 DATASETS
立体匹配深度估计 DEPTH BY STEREO MATCHING
基于立体匹配的深度重建方法采用 $n =2 $ 个 RGB 图像,并生成视差图 $D$ 使得以下的能量函数最小化:
其中,$x$ 和$y$ 代表像素,$\mathcal{N}_{x}$ 代表 $x$ 附近的像素
式子前面部分代表了 匹配误差 (matching cost) ,在使用修正过的图像对时【水平校正】 $C(x,d_{x})$ 计算 左图 $x=(i,j)$和 右图$y=(i,j-d_x)$ 之间的 匹配误差。
$d_{x}=D(x)\in [d_{min},d_{max}]$ 代表了 $x$ 像素的视差,然后通过三角测量就能计算出深度
将视差离散化成 $n_d$ 个视差等级,$C$ 变为 $W × H × n_d $大小的 3D 代价体积(cost volume)
In the more general multiview stereo case, i.e., $n ≥ 2$, the cost $C(x, d_x)$ measures the inverse likelihood of x on the reference image having depth $d_x$.
方程的第二项是正则化项,用于施加诸如 平滑度和左右一致性(smoothness and left-right consistency) 之类的约束。
传统上,这个问题是通过 四个模块 (building blocks)的流水线(pipeline)来解决的,(1)特征提取,(2)跨图像的特征匹配,(3)视差计算,以及(4)视差细化和后处理。
前两个模块构建代价体积$C$。第三个块对代价体积进行正则化,然后通过最小化能量方程方程来找到 视差图的初始估计。最后一个块对初始视差图进行细化和后处理。
学习特征提取和匹配 Learning feature extraction and matching
早期用于立体匹配的深度学习方法 用学习的特征 替代了 手工设计的特征。
从左右视图上截取一个patch,分别以 $x=(i,j)$和$y=(i,j-d)$ 为中心,其中$d \in \{0,1,…,n_d\}$
用CNN计算他们对应的特征向量,用 L1 正则、L2正则、相关性指标、或者上层网络学习的指标 生成一个相似程度的分数 $C(x,d)$
两个patch可以同时或者分开训练
基本网络架构 The basic network architecture
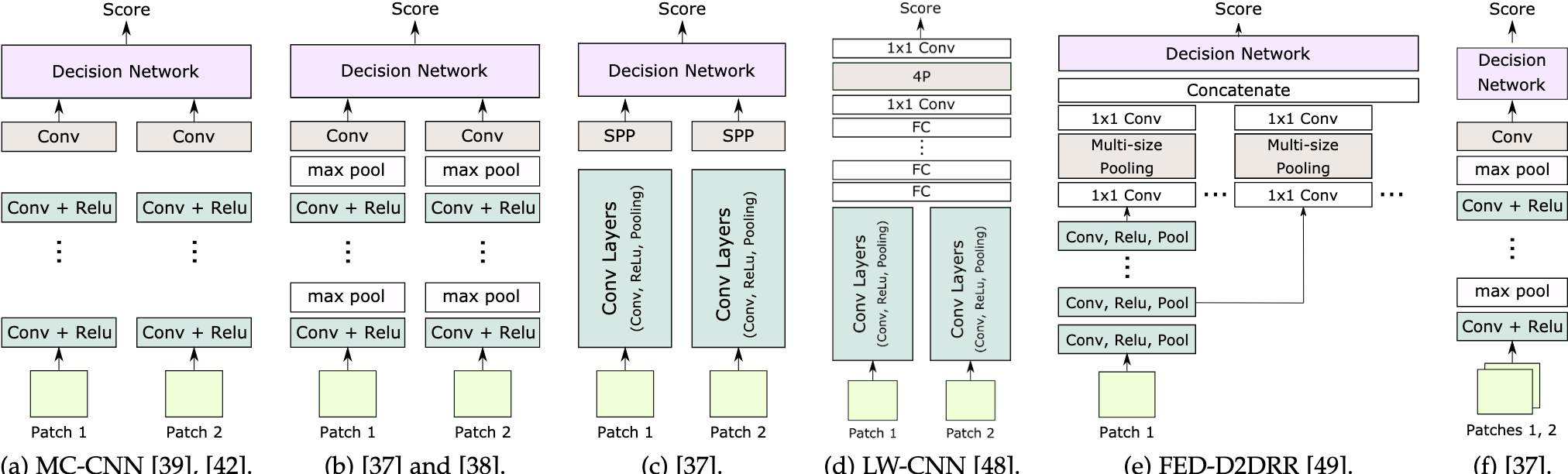
- 最基本的结构 基本的网络结构如(a)图所示,由两个CNN分支组成,从左图取以$x=(i,j)$为中心的patch,从右图取以$y=(i,j-d)$为中心的patch,进行特征提取,其中$d\in [d_{min},d_{max}]$
- J. Zbontar and Y. LeCun, “Computing the stereo matching cost with a convolutional neural network,” in IEEE CVPR, 2015, pp. 1592–1599.
- J. Zbontar and Y. LeCun, “Stereo matching by training a convolutional neural network to compare image patches,” Journal of Machine Learning Research, vol. 17, no. 1-32, p. 2, 2016.
以上工作使用四层CNN作为encoder,每一层除了最后一层,用ReLU作为激活函数
- 对(a)进行改进 改进的结构如(b)、(c)所示
- S. Zagoruyko and N. Komodakis, “Learning to compare image patches via convolutional neural networks,” in IEEE CVPR, 2015, pp. 4353–4361.
- X. Han, T. Leung, Y. Jia, R. Sukthankar, and A. C. Berg, “MatchNet: Unifying feature and metric learning for patch-based matching,” in IEEE CVPR, 2015, pp. 3279–3286.
以上工作使用了这种结构,它与(a)基本一致,由以下不同:
- (b)除了最后一层,在CNN之后都增加了max pooling 和 subsampling,这样可以处理更大的patch以及不同视图(pointview)中更大的变化
- (c)每个特征提取分支末端使用空间金字塔池化(SPP)模块,这样模型可以处理不同大小的patch,生成固定大小的feature,它的作用是通过空间池化,将最后一个卷积层的特征聚合到一个固定大小的特征网格中
The module is designed in such a way that the size of the pooling regions varies with the size of the input to ensure that the output feature grid has a fixed size independently of the size of the input patch or image. Thus, the network is able to process patches/images of arbitrary sizes and compute feature vectors of the same dimension without changing its structure or retraining.
将学习到的特征使用各种方法进行相似度的计算:
- $L_2$ distance
- cosine distance
- the (normalized) correlation distance(inner product)
相关性 相对于 $L_2$ 的好处在于可以用2D或者1D的卷积层来实现(correlation layer),相关层不需要训练,以下论文使用了这种技术
- N. Mayer, E. Ilg, P. Hausser, P. Fischer, D. Cremers, A. Dosovitskiy, and T. Brox, “A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation,” in IEEE CVPR, 2016, pp. 4040–4048.
- J. Zbontar and Y. LeCun, “Computing the stereo matching cost with a convolutional neural network,” in IEEE CVPR, 2015, pp. 1592–1599.
- E. Simo-Serra, E. Trulls, L. Ferraz, I. Kokkinos, P. Fua, and F. Moreno-Noguer, “Discriminative learning of deep convolutional feature point descriptors,” in IEEE ICCV, 2015, pp. 118126.
- J. Zbontar and Y. LeCun, “Stereo matching by training a convolutional neural network to compare image patches,” Journal of Machine Learning Research, vol. 17, no. 1-32, p. 2, 2016.
- W. Luo, A. G. Schwing, and R. Urtasun, “Efficient deep learning for stereo matching,” in IEEE CVPR, 2016, pp. 5695–5703.
- 决策层优化
使用最近的研究没有使用手工制作的相似性度量,而是使用了由全连接(FC)层组成的决策网络,该层可以实现为1×1卷积、全卷积层或卷积层,然后是全连接层。 在所有情况下,由特征编码模块的两个分支计算的特征首先被连接(concat)起来,然后被馈送到顶部网络。
以下网络 使用均值池化来聚合来自多个补丁的特征,然后再将它们提供给决策网络。
W. Hartmann, S. Galliani, M. Havlena, L. Van Gool, and K. Schindler, “Learned multi-patch similarity,” in IEEE ICCV, 2017, pp. 1595–1603.
网络架构变体 Network architecture variants
- ConvNet vs. ResNet
A. Shaked and L. Wolf, “Improved stereo matching with constant highway networks and reflective confidence learning,” in IEEE CVPR, 2017, pp. 4641–4650.
- Enlarging the receptive field of the network
- H. Fu, M. Gong, C. Wang, K. Batmanghelich, and D. Tao, “Deep Ordinal Regression Network for Monocular Depth Estimation,” in IEEE CVPR, June 2018.
- H. Park and K. M. Lee, “Look wider to match image patches with convolutional neural networks,” IEEE Signal Processing Letters, vol. 24, no. 12, pp. 1788–1792, 2017.
- X. Ye, J. Li, H. Wang, H. Huang, and X. Zhang, “Efficient stereo matching leveraging deep local and context information,” IEEE Access, vol. 5, pp. 18 745–18 755, 2017.
Ye等[49]将SPP模块放置在每个特征计算分支的末尾,参见图2-(c)和(e)。这样,每个补丁只计算一次。,此外,Ye等[49]采用多个具有不同窗口大小的单步池化到不同的层,然后将它们的输出连接起来以生成特征图,见图2-(e)。
-
Learning multiscale features:
-
Reducing the number of forward passes
-
Learning similarity without feature learning:
训练过程 Training procedures
-
Supervised training
-
Weakly supervised learning
端到端的立体深度估计