PromptKD:Unsupervised Prompt Distillation for Vision-Language Models

主要贡献
https://zhengli97.github.io/PromptKD/chinese_interpertation.html
- 重用 teacher CLIP 产生的text feature用于学生的训练和推断。这样确保了text feature高质量的同时,还显著的节省计算量,训练时只涉及student的image encoder。
- 对齐学生和教师的logits,以便于更好地指导学生.
- 用大量的无标签 domain data来训练学生,在训练时,使用数据集的全量数据作为无标签数据进行蒸馏,prompt就可以学到更广泛的domain knowledge。高性能的教师CLIP保证了用于蒸馏的软标签的准确性。
相关工作
Prompt Learning in Vision-Language Models
prompt learning 是一种可以将大型预训练模型(例如 CLIP )转移到下游任务 ,而不需要完全重新训练原始模型的技术。
下游任务:分类、目标检测、dense prediction……
Zero-shot Learning
给定已见类别的标记训练集,零样本学习(ZSL)旨在学习一个可以对未见类别的测试样本进行分类的分类器。可以分为Inductive and Transductive ZSL.
之前关于prompt learning 的工作,例如 MaPLe 和 PromptSRC,主要集中在实例归纳设置(nstance inductive settings),其中只有 标记的训练实例 可用。
Knowledge Distillation
知识蒸馏旨在 在大型预训练教师模型的监督下训练轻量级学生模型。
模型&方法
本文首先探索提示作为一种有效的知识提取器,允许 CLIP 学生模型通过调整对大量未标记域图像的预测来向大型 CLIP 教师模型学习。
具体来说,该方法方法包括两个主要阶段:教师预培训阶段和学生提示蒸馏阶段。
-
在少量的数据上预训练大型CLIP模型
-
将教师clip 的text encoder 的文本特征保存作为class vectors
-
在之后的阶段中,将class vector 和学生CLIP的图像编码结果相乘,重用class vector 从而得到每个模型的预测
-
通过 prompting prompt imitation 来 initiate 蒸馏过程,让学生模型产生和老师模型相似的预测
-
引入额外的投影器来对齐教师的文本特征和学生的图像特征
-
最后利用训练好的学生图像编码器和 存储的教师文本特征(class vector)来进行推理
背景知识
- VLM
CLIP做法:
数据集: labeled 图像识别数据集 $D=\{x_j,y_j\}_{j=1}^M$
其中有 $N$ 个类别名称 $c=\{c_i\}_{j=1}^N$ ,
CLIP的文字描述 $t_i$ 为 a photo of a $\{c_i\}$
文本编码: 将所有 $t_i$ 输入到文字编码器$f_T$ 中,得到mormalized 文本特征 $\omega_i=f_T(t_i)/||f_T(t_i)||_2\in \mathbb{R}^d$, $d$ 代表特征的维度
完整的文本特征:$\mathrm{W} = ~\big[w_{1},,,w_{2},,\dots,,w_{N}\big] \in \mathbb{R}^{N\times d}$ 可以当作分类图片的classfication weight vector
将图片$x$ 经过$f_I$ 图像编码器,得到normalized 图像特征 $u = f_I/||f_I(x)||_2 \in\mathbb{R}^d$
输出probability:
$p(y|x) = \frac{exp(uw_y^T/\tau)}{\sum_{i=1}^N exp(uw_i^T/\tau)}$
$uw^T$ 是logit 输出,$\tau$ 是温度参数
CoOp做法:
将类别 $c_i$ 的prompt $t_i$ 修改为$t_i = {v_1,v_2,…,v_M,c_i}$ 其中v_i 和词嵌入有相同的维度,M是超参数
v_i 是可以学习的 合适的 下游任务的 文本 软 提示
- KD
“Kullback-Leibler (KL) divergence” (Li 等, 2024, p. 4) (pdf) loss 用来描述两个模型输出的分布
$L_{k d}(q^{t},q^{s},\tau)=\tau^{2}K L(\sigma(q^{t}/\tau),\sigma(q^{s}/\tau)).$
其中$q^t,q^s$ 代表老师和学生的logits ,$\sigma(.)$ 是softmax ,$\tau $ 是温度参数,决定了分布的softness
PromptKD: Prompt Distillation for VLMs
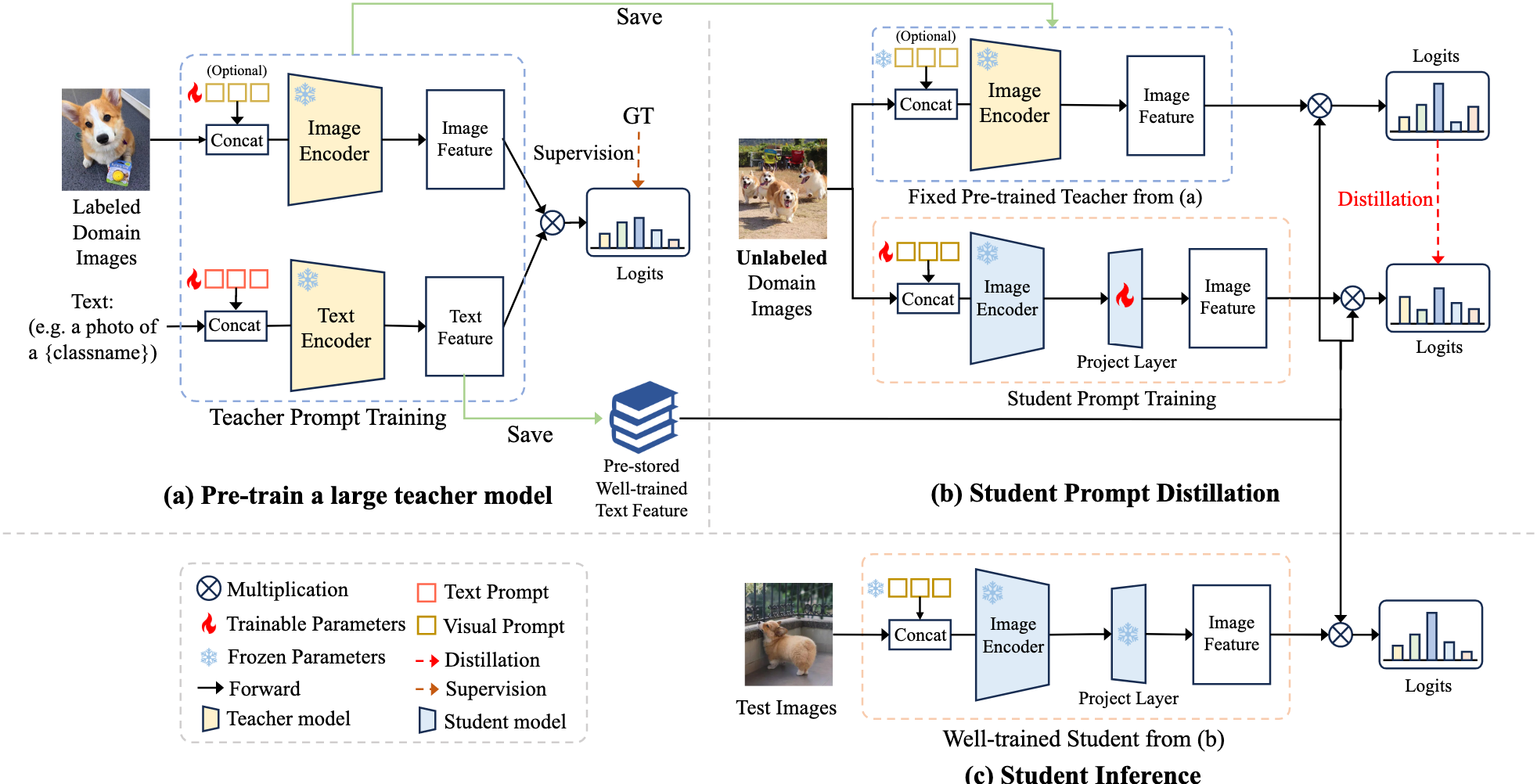
Teacher Pretraining
- 用标记好的domain data pre train 一个大的CLIP模型
用MaPLe和PromptSRC进行训练 或者训练好的公共CLIP,用有图片以及带有其类别的描述作为输入,通过文本$f_T^t$和图像$f_I^t$编码器得到归一化的图像特征和文本特征$u \in \mathbb{R}^d$ 、$w \in \mathbb{R}^d$
最终输出 $p^t$ 由下式算出
$p(y|x) = \frac{exp(uw_y^T/\tau)}{\sum_{i=1}^N exp(uw_i^T/\tau)}$
通常,通过最小化预测概率 p 和真实标签 y 之间的交叉熵损失来更新教师软提示的参数
当文本编码器训练好之后,保存训练好的输出特征。对所有N类别的文本特征$\mathrm{W} = ~\big[w_{1},,,w_{2},,\dots,,w_{N}\big] \in \mathbb{R}^{N\times d}$ 用于后续处理
此操作消除了学生 CLIP 文本分支的必要性,从而在训练过程中节省了大量的计算成本。此外,通过我们的PromptKD方法,我们可以用学生的轻量级图像编码器代替大型教师的重型图像编码器,降低部署期间的计算成本,同时保持有竞争力的性能。
Student Prompt Distillation
促使学生通过 prompt imitation 与教师的输出对齐
由于保存了 老师的 text feature ,只需要训练学生的图像编码器$f_I^S$ with learnable visual prompts 和 投影器
从没有标签的数据集中 将 x输入到预训练的老师和未训练的学生的图像branch,可以的到老师和学生的图像特征
$u^{t}= f_{I}^{t}(x)\big/||f_{I}^{t}(x)||_2\in\mathbb{R}^{d}$
$u^{s}= P(f_{I}^{s}(x))\big/|P(|f_{I}^{s}(x))||_2\in\mathbb{R}^{d}$
在学生的图像分支中,P()是投影器,以相对较小的成本匹配特征尺寸,同时足够有效以确保准确对准。
将预存好的老师文本特征 $W \in \mathbb{R}^{N\times d}$ 和 老师、学生图像特征的到 logits $q^t = u^tW^T\in\mathbb{R}^N$ $q^s = u^sW^T\in\mathbb{R}^N$
LOSS: $L_{stu} = L_{kd}(q^t,q^s,\tau)$
目标是让学生的q和老师的q尽量相似

讨论
pro:合理利用了大模型,给学生很好的zero-shot能力
con:当蒸馏数据缺乏目标域的表示时,蒸馏后的学生模型对该特定域的泛化能力可能会出现偏差或减弱。未来,计划探索潜在的正则化方法来缓解这些问题。