(AlexNet)ImageNet Classification with Deep Convolutional Neural Networks[2012]

Alexnet经典之作,卷积神经网络效果突飞,端到端的先驱
paper: ImageNet Classification with Deep Convolutional Neural Networks
简介
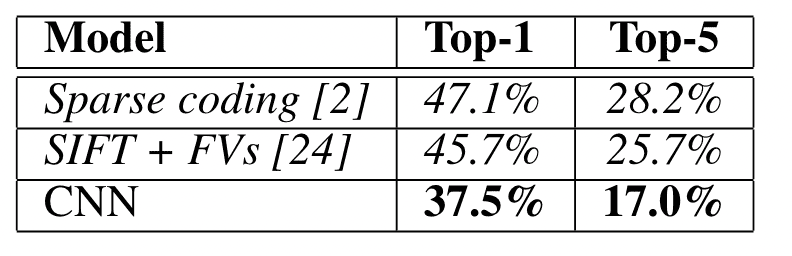
本文训练了一个深度卷积网络,使用ImageNet LSVRC-2010 中的1.7m高分辨图像进行了1000个类别的分类任务,top-1 和 top-5 错误率为 37.5% 和 17.0%。该模型使用5个卷积层和3个全连接层以及softmax。为了加速训练,使用了非饱和神经元(non-saturating neurons)和并行GPU的技巧,使用dropout和数据增强减轻全连接层中的过拟合。对原始图像进行裁切后直接使用原始RGB图像进行训练,而无需进行(label-preserving transformations)。
数据处理
- 将原始图像等比例缩小至短边长度为256
- 从结果图像中裁剪出中央 256 × 256 的块
- 直接使用原始像素值(raw RGB)进行训练
模型设计
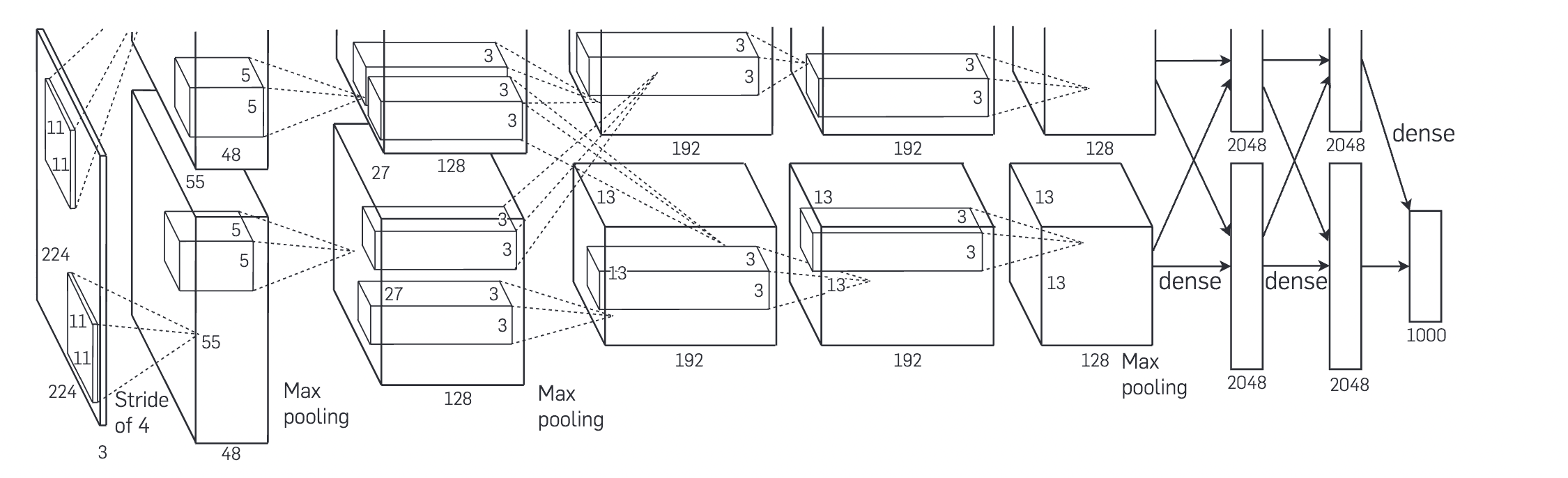
- 第一层使用96 个 11 × 11 × 3 的卷积核进行卷积stride为4,然后maxpooling
- 第二层使用256 个 5 × 5 × 48 卷积核,然后进行maxpooling
- 第三层使用384 个3 × 3 × 256卷积核
- 第四层使用384 个3 × 3 × 192卷积核
- 第五层使用256 个 3 × 3 × 192 卷积核,然后maxpooliing
- 全连接层使用两层4096个神经元,最后一层为1000个神经元,然后加上softmax以得到所有类别的概率分布
激活函数使用reLU
($$\operatorname{ReLU}(x) = \max(x, 0).$$)
在多个GPU上进行训练
- 在第一层,两个gpu分别承担一半的卷积核个数对上一层进行卷积(每个GPU输出一半的通道数48+48)
- 二层同理,对自己上次的输出进行卷积(128+128)
- 注意第三层,两个gpu对上一层两个gpu的输出结果都进行了卷积(256)
- 四五层与一二层同理,各自卷积自己的结果
局部标准化
本文认为,使用以下方式能提高模型的泛化性:
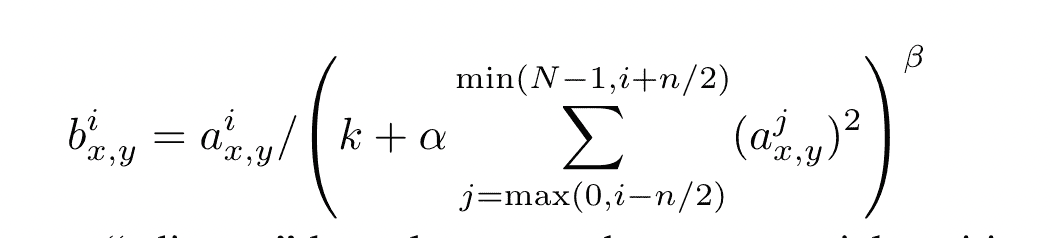
- N代表该层的卷积核个数
- x,y表示像素位置
- i,j表示卷积核的索引
- 本文设置 k = 2, n = 5, α = 10−4, and β = 0.75. 它们为超参数
总的来说,该方法使用一个周围几个内核的值来归一化卷积的值
重叠池化
s代表两个窗口的距离,z x z代表窗口的大小,当s = z,就是普通的池化操作 本文发现with s = 2 and z = 3 模型更不容易过拟合,效果要更好,但并未给出解释
减少过拟合
数据增强
本文使用了两种数据增强的方法,均使用原始图像进行变换,使用python处理,计算开销不大,也不需要存储在硬件上。
- 从256x256的图像中随机抽取224x224的图像
- 对RGB通道作PCA
dropout
本文在前两层MLP使用了dropout
在测试的时候,将所有的神经元输出都乘0.5,这是对使用dropout的近似估计
实验结果
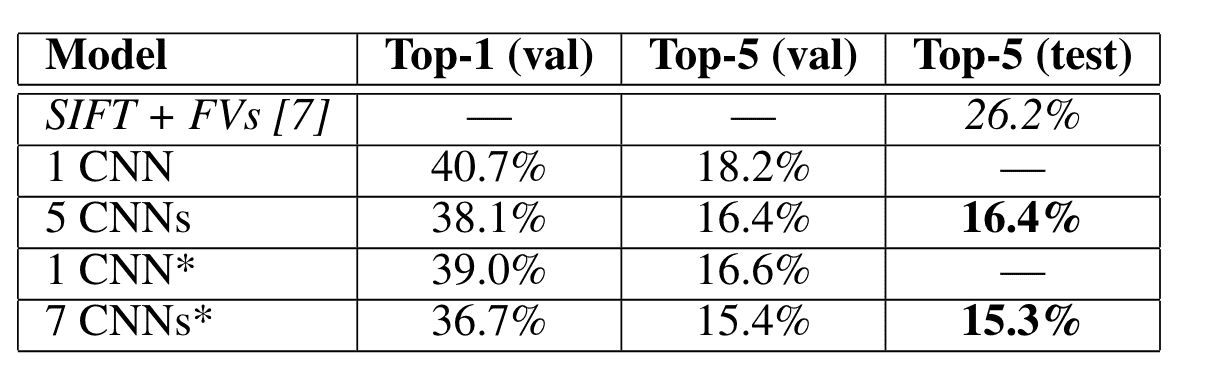
定量
定性



讨论
- 文中所说的非饱和神经元(non-saturating neurons)应该是指使用relu进行的激活,因为他叫relu为non-saturating nonlinearity
- 对于多GPU的方法如今看来有点画蛇添足,如今的硬件不需要进行这样繁琐的操作
- 直接使用raw RGB图像进行训练提高了模型的可解释性,我们能看到图像在网络中是如何一步步变换的
- 本文最后就是使用4096维的向量来表征所有的图像,可以理解为将原始图像信息进行了压缩,并且相似类别的向量距离更近,这与语义空间的概念极其吻合。